Earlier this week a colleague contacted me with an issue. One of his agency clients sent him a Translation Memory, but much to his dismay, the TM was cluttered with unnecessary formatting tags that rendered it pretty much useless. This clutter is usually being referred to as a “Tag soup”, and it is primarily the result of a PDF or image file conversion into formatted text. A Tag Soup could also form out of style mismatch when copying and pasting formatted text between applications, for example, copying an HTML email message and pasting it into a Word Processor. The conversion process or style mismatch introduces all kinds of unnecessary formatting tags that need to be removed in a post-processing stage before the converted document can be worked on. Emma Goldsmith wrote an excellent and exhaustive article about how to get rid of a tag soup in documents before starting to work on them, but what if the tag soup is already in the Translation Memory? The good news is that this issue can be resolved fairly easily. It is worth mentioning that the methods described here for removing the Tag Soup can also be used to remove legitimate formatting tags if such need ever arises.
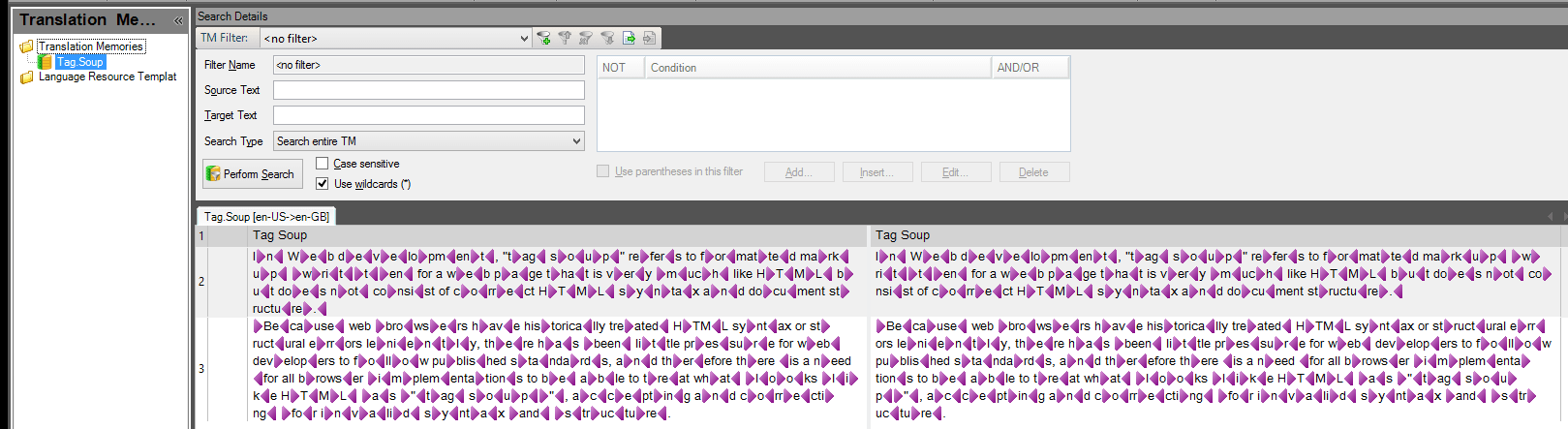
For the purpose of this demonstration I’ve prepared a ‘Tag Souped TM’. As evident from the screenshots below, this is quite an extreme case of a Tag Soup (although similar ones do exist in reality) because I wanted to show that the removal methods discussed here are effective even with a severe case of a Tag Soup. Furthermore, for ease of presentation the source and target languages in the Translation Memory are the same.
Although these methods are considered generally safe, before attempting to use any of them I recommend creating a backup copy of the TM, just in case something goes wrong.
Using SDL Studio
All versions of SDL Studio to date have a nifty little feature for removing these formatting tags from the TM.
- Switch to the Translation Memories view in SDL Studio (at the bottom of the left pane).
- Open the relevant TM from the File menu in Studio 2009 and 2011, from the Home tab and Tasks group of the Ribbon in Studio 2014, or by right clicking the Translations Memories folder in the Translation Memories pane and selecting the Open Translation Memory option in all versions.
- With the TM open, select the Batch Edit option from the File menu in Studio 2009 and 2011, the Home tab and Tasks group of the Ribbon in Studio 2014, or by right clicking the TM in the Translation Memories pane in all versions.
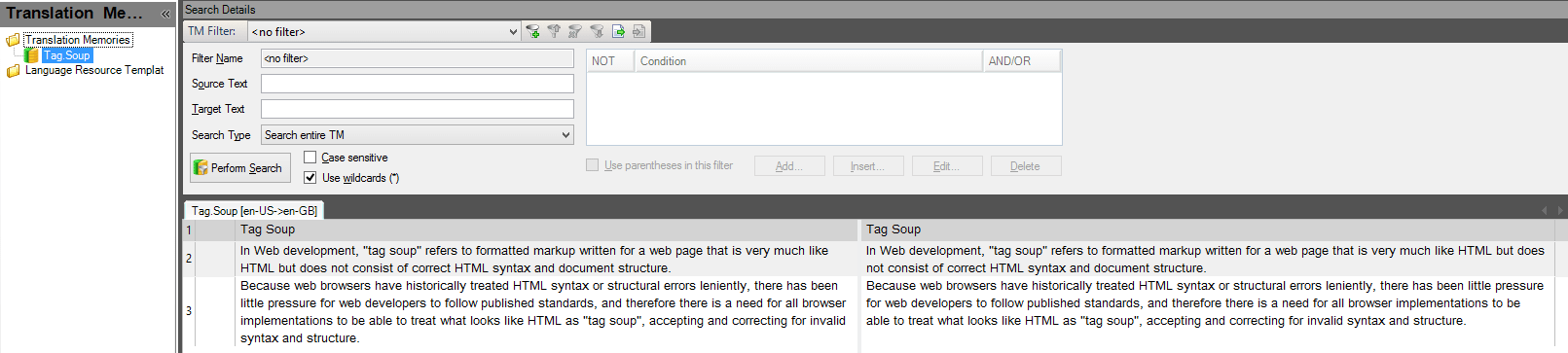
- In the Batch Edit window, click Add and select the Delete Tags options.
- The default setting deletes only the formatting tags. However, if for some reason placeholder tags should also be deleted (not a common scenario), select the Delete text placeholder tags checkbox. If unsure, leave this checkbox unchecked.

Exporting to TMX and using Olifant
The Tag Soup could be removed even if your Translation Environment Tool of choice doesn’t have a similar function to the one described above.
- Download and Install Olifant
- Export the TM to the Translation Memory eXchange (TMX) file format
- Start Olifant and open the TMX export file
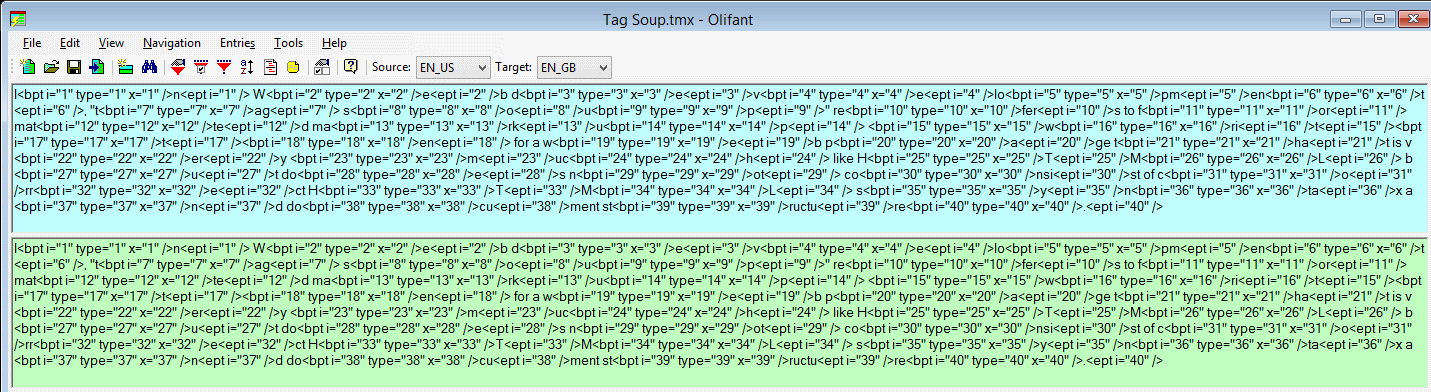
- With the TMX open, go to the Entries menu and select the Remove Codes option
- From the dialog box, select the Remove both TMX tags and their content option
- Save (or export to a new TMX file if you want to keep the original version) the clean TM and import it to your Translation Environment Tool of choice.
Before
After
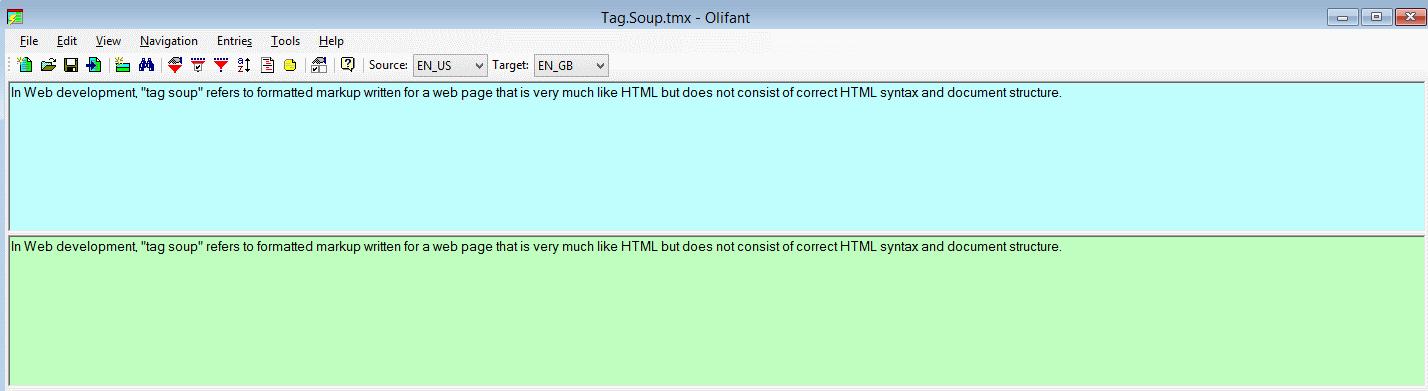
Please note:
- The screenshots and instructions are for the .NET version of Olifant. There is a also a newer Java based version of Olifant, but at the time of this writing it is only in Alpha stage and not yet ready for production.
- I’ve tested this method on Windows 8 and it didn’t work. It is therefore possible that the .NET version of Olifant is not fully compatible with Windows 8.
Using Regex
Regular expression (abbreviated Regex) is a very powerful method for manipulating text. Regex is a topic that goes well beyond the scope of this article, but it can be harnessed to search and delete these tags. To do that: Open the TM in your favorite Translation Environment Tool; the only prerequisite is that tool has to support Regex and allow direct (or batch) TM editing. Alternatively, export the TM inoto TMX and open it in a TMX editor such as the aforementioned Olifant. The Regex syntax for capturing the tags may vary depending on the way Regex is supported by the tool, but as a general guideline the syntax <[^>]*> is a good reference point that can be adapted as needed (for more information about Regex support, please consult the tool documentation). This syntax searches for everything enclosed withing the < and > characters, or in other words the tags. Now these tags can be deleted using a simple search and replace operation. I tested this syntax in Olifant and it seems to work.
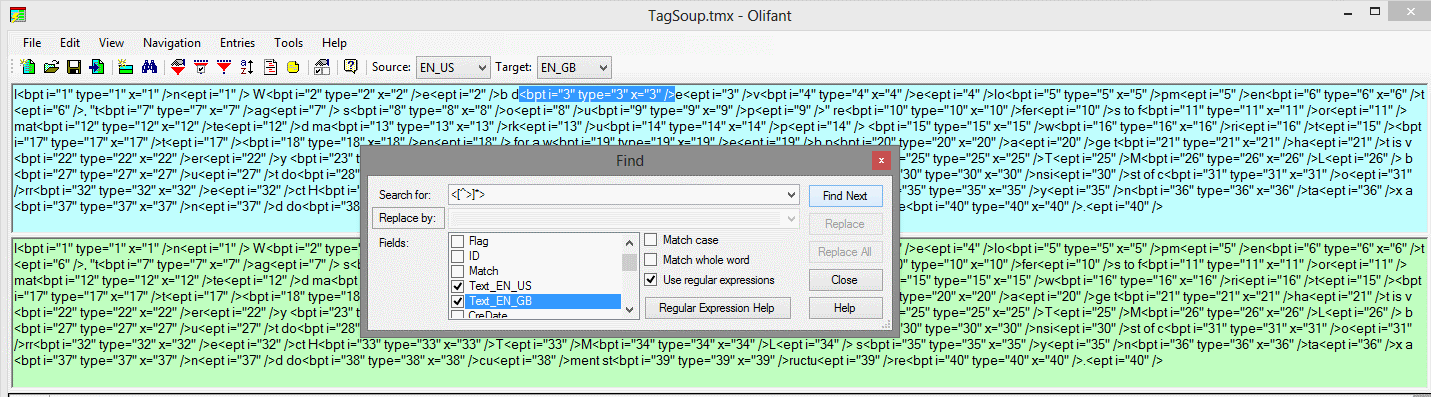
Although Tag Soup in a Translation Memory is less common than its document counterpart, knowing how to clean it might come in handy. In most cases either of the above methods, or in some extreme cases a combination of them, will be enough to remove the clutter and produce a much more usable TM.
Leave a Reply