Interoperability is a topic I took a special interest in since starting to use Translation Environment Tools (TEnTs). Most TEnTs store the data in proprietary file formats and that makes it that much harder to share or migrate information. One unfortunate results of this difficulty is the enablement of some unethical practices, and even more importantly, the creation of the feeling among users that they are held “captive” by the propriety formats and forced to use a certain tool over another regardless of their workflow needs or preferences, unless they are willing to spend time and effort applying workarounds that are almost never guaranteed to work, or worse, invest money in tools just for using their filters in the pre-processing stage. This resonates hard with me because I’m strongly against what I believe is a harmful, damaging, misleading, delusional, and near-sighted infatuation with technology that puts the technology before the human professional. I believe that the human professional is the most important element in any professional activity and that the technology is just there to help the professional as a tool. Therefore, the professional must be able to choose his or her tools by merit, experience, and expertise with as little as possible artificial obstacles influencing the decision.
In recent years quite a few advancements have been made in terms of TEnTs interoperability. It was probably promoted by the increased range of available TEnTs in the market and the emphasize that some developers have put into better standards supports and interoperability from the get go. Nowadays most modern Translation Environment Tools can exchange information via standardized file formats – primarily XLIFF (for bilingual files) and TMX (for exchanging Translation Memory information) – and some of them even offer native or extendable (via add-ons) support for reading and writing proprietary formats of other TEnTs.
In that regard it is worth noting that contrary to common belief, irritating as they sometimes are, proprietary file formats are not used just to restrict users; they allow the developers to extended the functionality of the standard file formats and add features that users need, rely on, and come to expect.
It is not the ideal situation, and there is still a long way to go in terms of improved (dare I say complete?) interoperability, but we have come a long way since just even 5 years ago.
For example, MemoQ can natively handle Studio SDLXLIFF and SDLPPX (Studio Package file format), as well as WordFast Professional TXML files; OmegaT through the Okapi Filters Plug-in can be extended to support additional file types; SDL Studio file support can be extended by installing additional File Type Definitions from the Open Exchange platform; and other TEnTs such as Fluency and Déjà Vu also offer some degree of interoperability, but I don’t have enough experience with them to comment in detail. Since XML has become the de-facto format for storing and exchanging information, the modern TEnTs can create customized XML file definitions to parse virtually any XML-based file, even when no native or extendable interoperability exist. And to complement this improved interoperability and extendability, the information can also be exchanged via the standardized file formats.
The interoperability is not flawless, and exchanging information still not always as smooth as it should be, but we have come a long way, indeed.
A couple of days ago I helped a colleague setup a WordFast project in Studio 2014 and thought to share the experience as a short case study that highlights the process and the basic approach. This process can be used to add support for MemoQ MQXLIFF files, as well as any other file type available through the SDL Open Exchange platform.
Installing New File Definitions in Studio
From my experience at the time of this writing, the most common proprietary TEnT file types that exchange hands in the market are SDL Studio’s SDLXLIFF and SDLPPX (Studio Package), WordFast’s TXML, and MemoQ’s MQXLIFF. SDL Studio does not natively support proprietary file formats of other TEnTs, but its support can be extended by installing additional file definitions:
- Login to your SDL Account, download the MemoQ
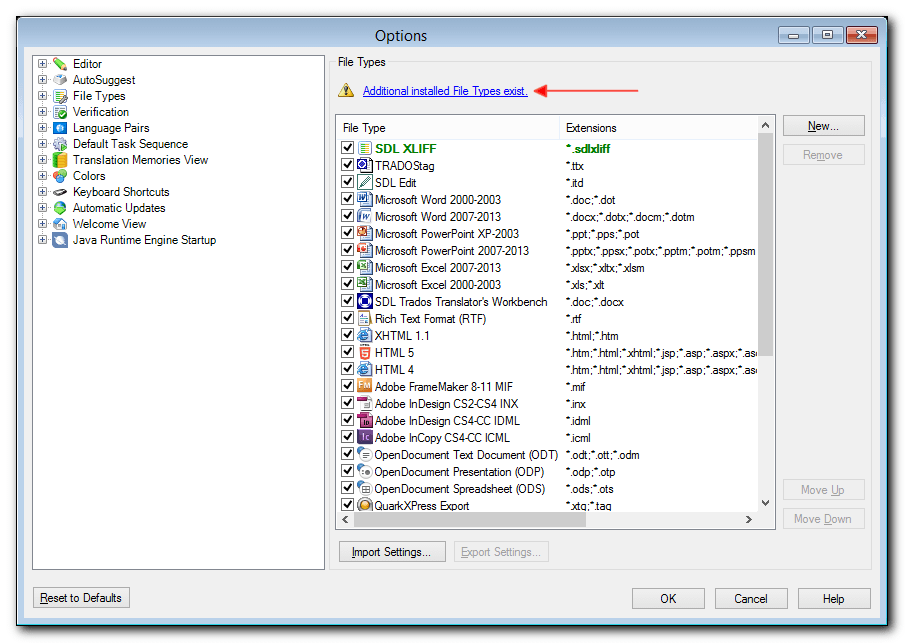
XLIFF and/or Wordfast Professional TXML file definitions, and install them; - Once installed, the new file type(s) should appear in Studio’s File Types list accessible through the
File > Optionsmenu; - If the newly or previously installed file types are not listed, check if the message Additional installed File Types exist is displayed on the right pane of the Options window. Sometimes Studio software updates visually reset the File Types list, but no need to panic, the installed file definitions are all still there;
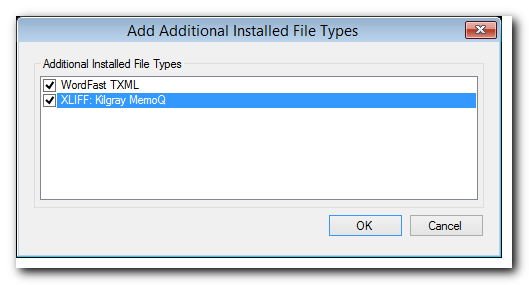
- Click the Additional installed File Types exist message and select all the required file types, and click
OKto confirm; - Now, all the additional file types should be displayed in the File Types List.
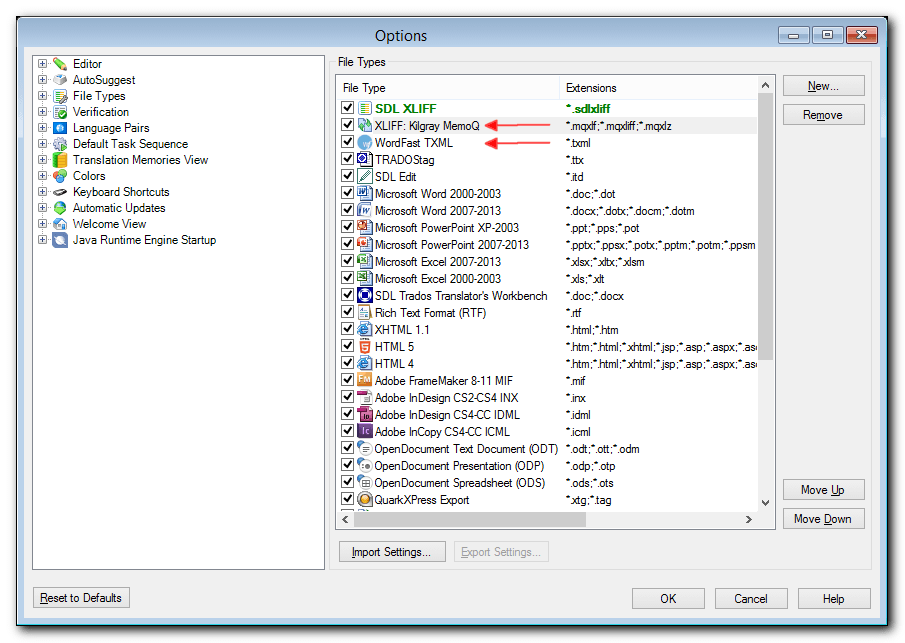
In this WordFast case study the text for translation was provided as a WordFast Professional TXML file, and after installing the TXML file definition Studio was able to read and write it without any issue. Note that Studio still converts the TXML into a SDLXLIFF file, so when the work is done make sure to save the file back in its original format by using the Save As Target… (Ctrl+F12) command or finalizing the project through the Batch Tasks menu.
Migrating Translation Memories
Modern TEnTs support the Translation Memory eXchange (TMX) format for storing and exchanging Translation Memory information. The TMX doesn’t support all the extended metadata that some proprietary TM file formats support, so when exporting a TM as TMX some metadata, such as custom fields and attributes, might be lost. However, TMX files generally make sharing and migrating Translation Memory information easier, especially if the TM doesn’t support proprietary metadata fields. Personally, I try to maintain my TMs free of any critical proprietary metadata. I know that some use the Client and Project fields to create some internal structure and separation within a large TM, but I always found it a bit restricting both in terms of my workflow as well as in terms of “future-proofing” the content; even more so nowadays that all modern TEnTs allow to use more than one TM (the historic limitation of SDL Trados 2007 or earlier) so the user can add as many many TMs as needed as reference. Another recommendation is to create an Exclusion file (in Studio, in other tools this information might be available in another form) when importing a TMX file. The exclusion file stores all the TM segments that failed to import for one reason or another, and makes it easier to get a quick overview of what was left out, to identify possible problem patterns, and determine if the failed segments are even worth stressing over.
Legacy Formats
Although they will naturally become less prevalent with time, it is still important to understand how to handle legacy TM formats. New generations of TEnTs can import information that was created their previous generation of technology; Studio for example can “upgrade” – i.e. convert – legacy SDL Trados TMs (in the TXT and MDW file formats) to its new SDLTM file format, but it cannot read TMs that were created by other TEnTs, unless they are in the TMX file format. Because past generations didn’t usually care much for open standards and interoperability, dealing with legacy formats could be a problem.
In this WordFast case study the TM was provided in the legacy TXT format of WordFast Classic. Although both WordFast Classic and SDL Trados 2007 or earlier can store the TM content in a plain text file, the data is structured differently and therefore Studio and WordFast Classic cannot read the legacy TMs of each other.
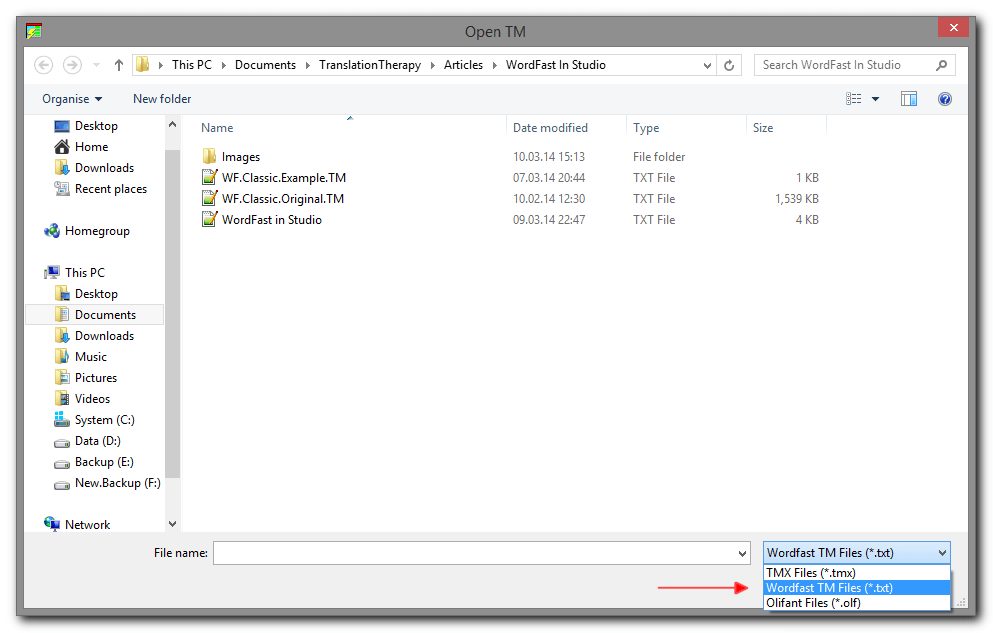
To overcome this obstacle I have used Olifant to convert the legacy WordFast Classic TM into a TMX file, and imported the TMX file into Studio:
- Download and install Olifant;
- Open Olifant and go to
File > Open; - From the File Types dropdown menu at the bottom of the screen select WordFast TM Files (.txt), and then select the TM you want to convert;
- Once the TM is opened in Olifant, quickly go through it to make sure that there are no major obvious character encoding issues (a potential problem when dealing with plain text files, especially for non-Latin languages), and then use the
File > Exportcommand to save the content in a TMX file.
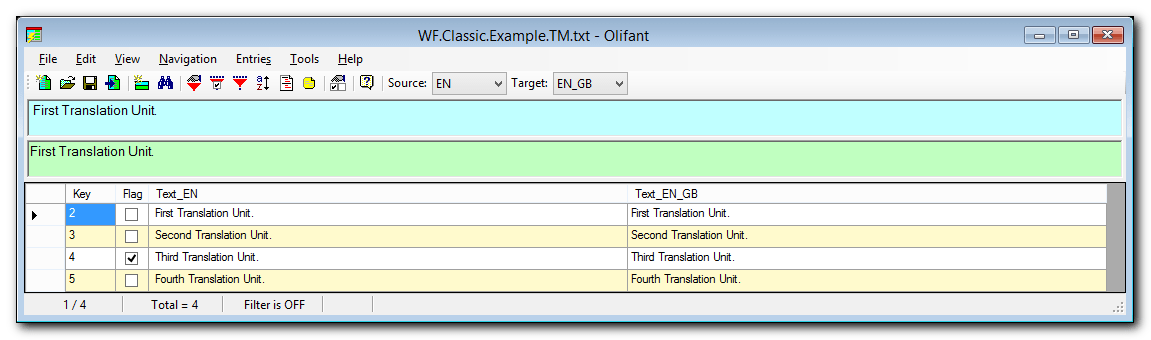
In this WordFast case study only one out of approximately 3,000 segments filed to imported. When consulting the Exclusion file I’ve immediately noticed that this segment contained Gibberish character in the target segment, probably due to some encoding mishap somewhere along the life cycle of the original TM, and it was certainly not something worth stressing over trying to fix.
Now, with the new file definition installed and the legacy WordFast Classic TM safely imported into Studio, what seemed at first as a discouraging project that will take some doing and “Tools-hopping”, turned out to be quite simple to setup and complete in full within Studio’s Editor Environment, which in this case was the TEnT of choice.
Terminology
Sharing or migrating Terminology could be a bit more complicated because the terminology management modules of the various TEnTs not all support a standardized file format for exchanging terminology with all of its metadata (custom fields and structure). In terminology work, especially with more complex structured glossaries/term-bases, the medtadata could be a critical component, so the lack of of full metadata support require some more careful attention and planning before exporting and importing that information. With this limitation in mind, the safest and probably easiest way to share and migrate terminology information is via a delimited file type such as a Comma-Separated Values (CSV) file. For exchanging simple structured glossaries (i.e. a source term field and a target term field) sharing the information via a delimited file works perfectly.
In this WordFast case study there was no extenal glossary provided, but I used this opportunity to convert my colleague’s own glossary stored in a two-column Excel spreadsheet to a MultiTerm termbase. Because it was stored as a two-column spreadsheet the information could have been easily converted into a MultiTerm TermBase using the MultiTerm Converter Tool, but to simplify the process even more I opted to use the Open Exchange application Glossary Converter. The Glossary Converter application automatically converts a terminology file (supporting xls, xlsx, csv, txt [tab-delimited], TBX, UTX and even TMX file types) into a MultiTerm TermBase, and vice versa, by simply dragging and dropping the file onto the application window.

It cannot be any easier.
Conclusion
Interoperability has come a long way in recent years, but still has a way to go. The improved interoperability is a very important development because it removes or at least minimizes some of the artificial obstacles, barriers and limitations that users have faced and that, in part, contributed to the unhealthy focus on technology. Technology is just an enabler, not the destination.
In this article I offered a short overview of TEnTs interoperability, as well as Studio-specific short case study that describes how a confusing and somewhat discouraging project that involved files that were created by different generations of another tool has turned into a straightforward Studio project.
To end this article on a positive note, my colleague reported that everything went smoothly and flawlessly, and that the project was a complete success.
What is your experience, good or bad, with TEnTs interoperability?
Leave a Reply